In order to prevent others from suffering from a similar misapplication of creative genius, what I’m going to look at here is :
- How Oracle caches table data in Memory
- How to work out what tables are in the cache
- Ways in which you can “pin” tables in the cache (if you really need to)
Fortunately, Oracle memory management is fairly robust so there will be no mention of leeks …
Data Caching in Action
Let’s start with a simple illustration of data caching in Oracle.
To begin with, I’m going to make sure that there’s nothing in the cache by running …
1 2 | alter system flush buffer_cache/ |
…which, provided you have DBA privileges should come back with :
1 | System FLUSH altered. |
Now, with the aid of autotrace, we can have a look at the difference between retrieving cached and uncached data.
To start with, in SQL*Plus :
1 2 | set autotrace onset timing on |
…and then run our query :
1 2 3 | select *from hr.departments/ |
The first time we execute this query, the timing and statistics output will be something like :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ...27 rows selected.Elapsed: 00:00:00.08...Statistics---------------------------------------------------------- 106 recursive calls 0 db block gets 104 consistent gets 29 physical reads 0 redo size 1670 bytes sent via SQL*Net to client 530 bytes received via SQL*Net from client 3 SQL*Net roundtrips to/from client 7 sorts (memory) 0 sorts (disk) 27 rows processed |
If we now run the same query again, we can see that things have changed a bit…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ...27 rows selected.Elapsed: 00:00:00.01...Statistics---------------------------------------------------------- 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 1670 bytes sent via SQL*Net to client 530 bytes received via SQL*Net from client 3 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 27 rows processed |
The second run was a fair bit faster. This is mainly because the data required to resolve the query was cached after the first run.
Therefore, the second execution required no Physical I/O to retrieve the result set.
So, exactly how does this caching malarkey work in Oracle ?
The Buffer Cache and the LRU Algorithm
The Buffer Cache is part of the System Global Area (SGA) – an area of RAM used by Oracle to cache various things that are generally available to any sessions running on the Instance.
The allocation of blocks into and out of the Buffer Cache is achieved by means of a Least Recently Used (LRU) algorithm.
You can see details of this in the Oracle documentation but, in very simple terms, we can visualise the workings of the Buffer Cache like this :
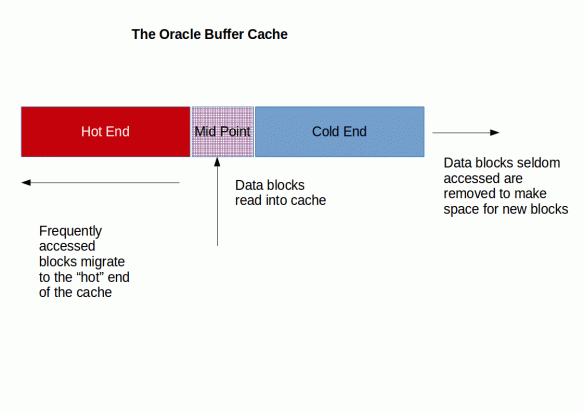
When a data block is first read from disk, it’s loaded into the middle of the Buffer Cache.
If it’s then “touched” frequently, it will work it’s way towards the hot end of the cache.
Otherwise it will move to the cold end and ultimately be discarded to make room for other data blocks that are being read.
Sort of…
THE SMALL TABLE THRESHOLD
In fact, blocks that are retrieved as the result of a Full Table Scan will only be loaded into the mid-point of the cache if the size of the table in question does not exceed the Small Table Threshold.
The usual definition of this ( unless you’ve been playing around with the hidden initialization parameter _small_table_threshold) is a table that is no bigger than 2% of the buffer cache.
As we’re using the default Automated Memory Management here, it can be a little difficult to pin down exactly what this is.
Fortunately, we can find out (provided we have SYS access to the database) by running the following query :
1 2 3 4 5 6 7 8 9 10 11 12 13 | select cv.ksppstvl value, pi.ksppdesc descriptionfrom x$ksppi piinner join x$ksppcv cvon cv.indx = pi.indxand cv.inst_id = pi.inst_idwhere pi.inst_id = userenv('Instance')and pi.ksppinm = '_small_table_threshold'/VALUE DESCRIPTION---------- ------------------------------------------------------------589 lower threshold level of table size for direct reads |
The current size of the Buffer Cache can be found by running :
1 2 3 4 5 6 7 8 | select component, current_sizefrom v$memory_dynamic_componentswhere component = 'DEFAULT buffer cache'/COMPONENT CURRENT_SIZE---------------------------------------------------------------- ------------DEFAULT buffer cache 251658240 |
Now I’m not entirely sure about this but I believe that the Small Table Threshold is reported in database blocks.
The Buffer Cache size from the query above is definitely in bytes.
The database we’re running on has a uniform block size of 8k.
Therefore, the Buffer Cache is around 614 blocks.
This would make 2% of it 614 blocks, which is slightly more than the 589 as being reported as the Small Table Threshold.
If you want to explore further down this particular rabbit hole, have a look at this article by Jonathan Lewis.
This all sounds pretty good in theory, but how do we know for definite that our table is in the Buffer Cache ?
What’s in the Buffer Cache ?
In order to answer this question, we need to have a look at the V$BH view. The following query should prove adequate for now :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | select obj.owner, obj.object_name, obj.object_type, count(buf.block#) as cached_blocksfrom v$bh bufinner join dba_objects obj on buf.objd = obj.data_object_idwhere buf.class# = 1 -- data blocksand buf.status != 'free'and obj.owner = 'HR'and obj.object_name = 'DEPARTMENTS'and obj.object_type = 'TABLE'group by obj.owner, obj.object_name, obj.object_type/OWNER OBJECT_NAME OBJECT_TYPE CACHED_BLOCKS-------------------- -------------------- -------------------- -------------HR DEPARTMENTS TABLE 5 |
Some things to note about this query :
- the OBJD column in v$bh joins to data_object_id in DBA_OBJECTS and not object_id
- we’re excluding any blocks with a status of free because they are, in effect, empty and available for re-use
- the class# value needs to be set to 1 – data blocks
So far we know that there are data blocks from our table in the cache. But we need to know whether all of the table is in the cache.
Time for another example…
We need to know how many data blocks the table actually has. Provided the statistics on the table are up to date we can get this from the DBA_TABLES view.
First of all then, let’s gather stats on the table…
1 | exec dbms_stats.gather_table_stats('HR', 'DEPARTMENTS') |
… and then check in DBA_TABLES…
1 2 3 4 5 6 7 8 9 | select blocksfrom dba_tableswhere owner = 'HR'and table_name = 'DEPARTMENTS'/ BLOCKS---------- 5 |
Now, let’s flush the cache….
1 2 | alter system flush buffer_cache/ |
…and try a slightly different query…
1 2 3 4 5 6 7 | select *from hr.departmentswhere department_id = 60/DEPARTMENT_ID DEPARTMENT_NAME MANAGER_ID LOCATION_ID------------- ------------------------------ ---------- ----------- 60 IT 103 1400 |
We can now use the block total in DBA_TABLES to tell how much of the HR.DEPARTMENTS table is in the cache …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | select obj.owner, obj.object_name, obj.object_type, count(buf.block#) as cached_blocks, tab.blocks as total_blocksfrom v$bh bufinner join dba_objects obj on buf.objd = obj.data_object_idinner join dba_tables tab on tab.owner = obj.owner and tab.table_name = obj.object_name and obj.object_type = 'TABLE'where buf.class# = 1and buf.status != 'free'and obj.owner = 'HR'and obj.object_name = 'DEPARTMENTS'and obj.object_type = 'TABLE'group by obj.owner, obj.object_name, obj.object_type, tab.blocks/OWNER OBJECT_NAME OBJECT_TYP CACHED_BLOCKS TOTAL_BLOCKS---------- --------------- ---------- ------------- ------------HR DEPARTMENTS TABLE 1 5 |
As you’d expect the data blocks for the table will only be cached as they are required.
With a small, frequently used reference data table, you can probably expect it to be fully cached fairly soon after the application is started.
Once it is cached, the way the LRU algorithm works should ensure that the data blocks are constantly in the hot end of the cache.
In the vast majority of applications, this will be the case. So, do you really need to do anything ?
If your application is not currently conforming to this sweeping generalisation then you probably want to ask a number of questions before taking any precipitous action.
For a start, is the small, frequently accessed table you expect to see in the cache really frequently accessed ? Is your application really doing what you think it does ?
Whilst where on the subject, are there any rogue queries running more regularly than you might expect causing blocks to be aged out of the cache prematurely ?
Once you’re satisfied that the problem does not lie with your application, or your understanding of how it operates, the next question will probably be, has sufficient memory been allocated for the SGA ?
There are many ways you can look into this. If your fortunate enough to have the Tuning and Diagnostic Packs Licensed there are various advisor that can help.
Even if you don’t, you can always take a look at V$SGA_TARGET_ADVICE.
If, after all of that, you’re stuck with the same problem, there are a few options available to you, starting with…
The Table CACHE option
This table property can be set so that a table’s data blocks are loaded into the hot end of the LRU as soon as they are read into the Buffer Cache, rather than the mid-point, which is the default behaviour.
Once again, using HR.DEPARTMENTS as our example, we can check the current setting on this table simply by running …
1 2 3 4 5 6 7 8 9 | select cachefrom dba_tableswhere owner = 'HR'and table_name = 'DEPARTMENTS'/CACHE----- N |
At the moment then, this table is set to be cached in the usual way.
To change this….
1 2 3 4 | alter table hr.departments cache/Table HR.DEPARTMENTS altered. |
When we check again, we can see that the CACHE property has been set on the table…
1 2 3 4 5 6 7 8 9 | select cachefrom dba_tableswhere owner = 'HR'and table_name = 'DEPARTMENTS'/CACHE----- Y |
This change does have one other side effect that is worth bearing in mind.
It causes the LRU algorithm to ignore the Small Table Threshold and dump all of the selected blocks into the hot end of the cache.
Therefore, if you do this on a larger table, you do run the risk of flushing other frequently accessed blocks from the cache, thus causing performance degradation elsewhere in your application.
The KEEP Cache
Normally you’ll have a single Buffer Cache for an instance. If you have multiple block sizes defined in your database then you will have a Buffer Cache for each block size. However, you can define additional Buffer Caches and assign segments to them.
The idea behind the Keep Cache is that it will hold frequently accessed blocks without ageing them out.
It’s important to note that the population of the KEEP CACHE uses the identical algorithm to that of the Buffer Cache. The difference here is that you select which tables use this cache…
In order to take advantage of this, we first need to create a KEEP Cache :
1 2 3 4 | alter system set db_keep_cache_size = 8m scope=both/System altered. |
Note that, on my XE 11gR2 instance at least, the minimum size for the Keep Cache appears to be 8 MB ( or 1024 8k blocks).
We can now see that we do indeed have a Keep Cache…
1 2 3 4 5 6 7 8 | select component, current_sizefrom v$memory_dynamic_componentswhere component = 'KEEP buffer cache'/COMPONENT CURRENT_SIZE---------------------- ------------KEEP buffer cache 8388608 |
Now we can assign our table to this cache….
1 2 3 4 5 | alter table hr.departments storage( buffer_pool keep)/Table altered. |
We can see that this change has had an immediate effect :
1 2 3 4 5 6 7 8 9 | select buffer_poolfrom dba_tableswhere owner = 'HR'and table_name = 'DEPARTMENTS'/BUFFER_POOL---------------KEEP |
If we run the following…
1 2 3 4 5 6 7 8 | alter system flush buffer_cache/select * from hr.departments/select * from hr.employees/ |
…we can see which cache is being used for each table, by amending our Buffer Cache query…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | select obj.owner, obj.object_name, obj.object_type, count(buf.block#) as cached_blocks, tab.blocks as total_blocks, tab.buffer_pool as Cachefrom v$bh bufinner join dba_objects obj on buf.objd = obj.data_object_idinner join dba_tables tab on tab.owner = obj.owner and tab.table_name = obj.object_name and obj.object_type = 'TABLE'where buf.class# = 1and buf.status != 'free'and obj.owner = 'HR'and obj.object_type = 'TABLE'group by obj.owner, obj.object_name, obj.object_type, tab.blocks, tab.buffer_pool/ OWNER OBJECT_NAME OBJECT_TYPE CACHED_BLOCKS TOTAL_BLOCKS CACHE---------- -------------------- --------------- ------------- ------------ -------HR EMPLOYEES TABLE 5 5 DEFAULTHR DEPARTMENTS TABLE 5 5 KEEP |
Once again, this approach seems rather straight forward. You have total control over what goes in the Keep Cache so why not use it ?
On closer inspection, it becomes apparent that there may be some drawbacks.
For a start, the KEEP and RECYCLE caches are not automatically managed by Oracle. So, unlike the Default Buffer Cache, if the KEEP Cache finds it needs a bit more space then it’s stuck, it can’t “borrow” some from other caches in the SGA. The reverse is also true, Oracle won’t allocate spare memory from the KEEP Cache to other SGA components.
You also need to keep track of which tables you have assigned to the KEEP Cache. If the number of blocks in those tables is greater than the size of the cache, then you’re going to run the risk of blocks being aged out, with the potential performance degradation that that entails.
Conclusion
Oracle is pretty good at caching frequently used data blocks and thus minimizing the amount of physical I/O required to retrieve data from small, frequently used, reference tables.
If you find yourself in a position where you just have to persuade Oracle to keep data in the cache then the table CACHE property is probably your least worst option.
Creating a KEEP Cache does have the advantage of affording greater manual control over what is cached. The downside here is that it also requires some maintenance effort to ensure that you don’t assign too much data to it.
The other downside is that you are ring-fencing RAM that could otherwise be used for other SGA memory components.
Having said that, the options I’ve outlined here are all better than sticking a bolt through the neck of your application and writing your own database caching in PL/SQL.